- SoundStorm kann Dialoge mit unterschiedlichen Stimmen synthetisieren und eröffnet neue Möglichkeiten, wie zum Beispiel die Erstellung von Audioinhalten aus Text und realistischen Podcasts.
- Im Gegensatz zu seinem Vorgänger generiert SoundStorm Audio in 30-Sekunden-Blöcken, was die Effizienz erhöht.
- Er war ausgebildet mit einem großen Datensatz an Dialogen, der ein solides Verständnis der gesprochenen Sprache gewährleistet.
- SoundStorm ist doppelt so schnell wie das Vorgängermodell und kann in nur 30 Sekunden 0,5 Sekunden Audio erzeugen.
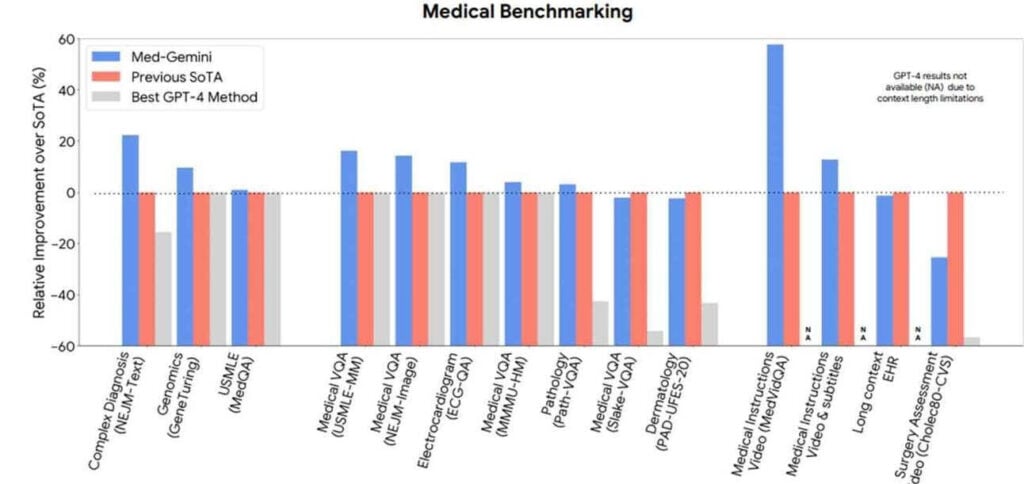
- Das Tool hat die breite Öffentlichkeit aber noch nicht erreicht Forschung Die vorgestellten Projekte zeigen, wie KI funktionieren sollte.
- Der von SoundStorm erzeugte Ton hat die gleiche Qualität wie das Vorgängermodell und gibt die Stimme des Sprechers genau wieder.
- Es ist wichtig, mögliche ethische Probleme zu berücksichtigen, wie z. B. Vorurteile im Zusammenhang mit Akzenten und Missbrauch bei der Nachahmung von Stimmen.
- O Google betont die Bedeutung der Implementierung von Schutzmaßnahmen und untersucht Möglichkeiten zur Erkennung der ethischen Nutzung dieser Technologie, beispielsweise durch Audio-Wasserzeichen.
- Hören Sie sich auf Englisch ein von SoundStorm generiertes Audiobeispiel an:
Siehe auch: