- SoundStorm can synthesize dialogues with different voices and open up new possibilities, such as creating audio content from text and realistic podcasts.
- Unlike its predecessor, SoundStorm generates audio in 30-second chunks, which increases efficiency.
- He was trained with a large dataset of dialogues, ensuring robust understanding of spoken language.
- SoundStorm is twice as fast as the previous model, capable of generating 30 seconds of audio in just 0,5 seconds.
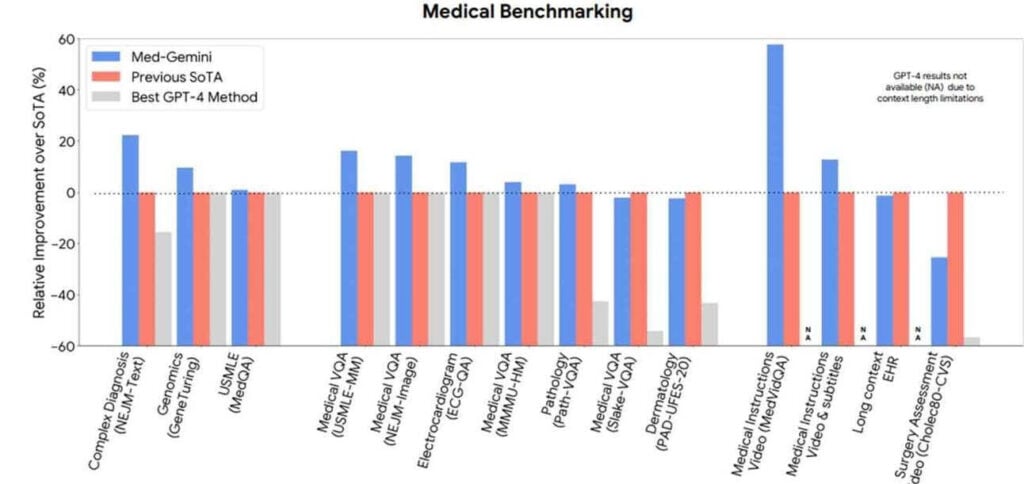
- The tool has not yet reached the general public, but research presented show how AI should work.
- The audio generated by SoundStorm is of equivalent quality to the previous model and accurately preserves the speaker's voice.
- It is important to consider possible ethical problems, such as biases related to accents and abuses in imitating voices.
- O Google highlights the importance of implementing protections and studies ways to detect the ethical use of this technology, such as audio watermarking.
- Listen, in English, to an example of audio generated by SoundStorm:
See also: