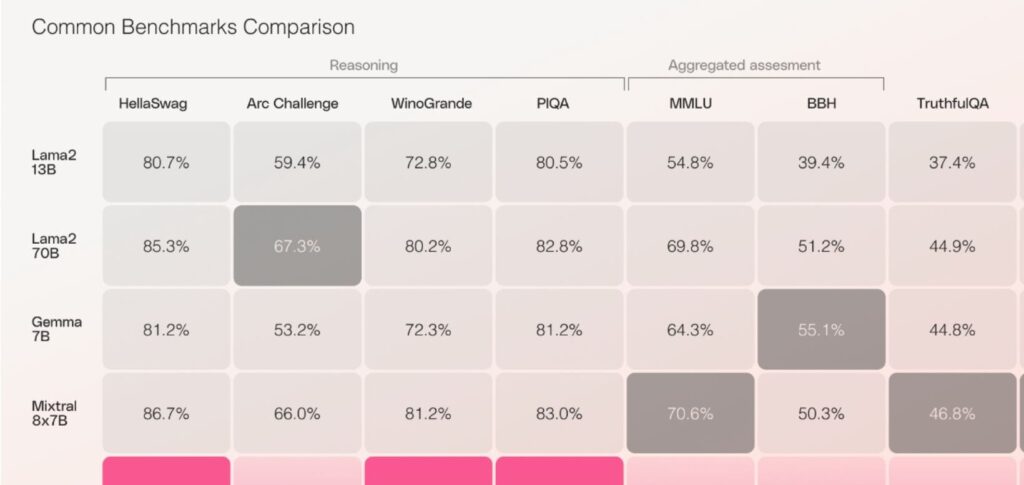
Jamba, com sua notável janela de contexto de 256K, equivalente a aproximadamente 105.000 palavras ou 210 páginas, destaca-se como um avanço significativo. Este modelo oferece um processamento três vezes mais rápido em contextos longos em comparação com modelos de tamanho semelhante baseados em transformadores.
PUBLICIDADE
🥂Meet Jambahttps://t.co/f2XZFOQbxh
— AI21 Labs (@AI21Labs) March 28, 2024
🔨Build with Jambahttps://t.co/n1FboI6Fm4
📝Read morehttps://t.co/5tX11qwEbp#Jamba #Mamba #Transformer #AIarchitecture #SSM
Sua eficiência é impressionante, necessitando apenas de uma única GPU com 80 GB de memória para operar, apesar da vasta extensão de sua janela de contexto. Isso representa um marco importante, tornando-o acessível e viável mesmo para configurações de hardware mais modestas.
Os pesos do Jamba estão prontamente disponíveis no HuggingFace, permitindo fácil acesso e implementação para aqueles interessados em explorar suas capacidades. Essa disponibilidade promete estimular ainda mais o desenvolvimento e a inovação na área de processamento de linguagem natural.
Leia também:



