A Hugging Face acaba de lançar uma grande atualização para o Open LLM Leaderboard, trazendo novos benchmarks e métodos de avaliação para lidar com a recente estagnação no progresso dos grandes modelos de linguagem (LLMs).
PUBLICIDADE
Detalhes da atualização
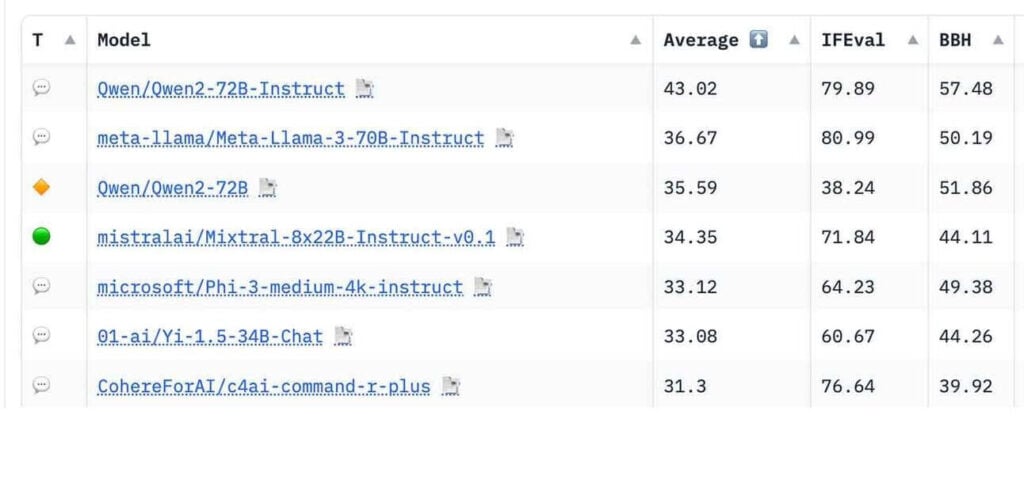
- Seis novos benchmarks foram adicionados ao ranking, projetados para serem mais desafiadores e menos suscetíveis a contaminação.
- O ranking inicial baseado nesses novos benchmarks mostra o Qwen2-72B-Instruct na liderança, seguido pelo Llama-3-70B-Instruct da Meta e Mixtral 8×22b.
- Um novo sistema de pontuação normalizada considera o desempenho básico dos modelos, permitindo uma comparação mais justa entre diferentes tipos de avaliação.
- A atualização também introduz a categoria “destaque do mantenedor” e um sistema de votação da comunidade para priorizar os modelos mais relevantes.
Por que isso é importante
À medida que os LLMs se aproximam do desempenho humano na maioria das tarefas, encontrar novas formas de avaliá-los torna-se mais difícil – e mais crucial. Essa reformulação ajuda a direcionar pesquisadores e desenvolvedores para melhorias mais focadas, fornecendo uma avaliação mais precisa das capacidades dos modelos.
Leia também: