
- De acordo com o projeto, apresentado no último dia 8, o MusicGen tem a capacidade de transformar prompts de texto em áudio, permitindo que usuários “criem” músicas de forma fácil e rápida.
- A ferramenta foi treinada utilizando 20 mil horas de música, incluindo 10 mil horas de músicas licenciadas e 390 mil faixas instrumentais.
- Além de permitir que você indique um instrumento para a música, um ritmo e a intensidade, é possível escolher a época que se passa a produção da faixa também.
- O MusicGen também permite a criação de faixas mais longas, servindo como ponto de referência inicial para os criadores.
- O conjunto de dados utilizado no treinamento do MusicGen veio de bibliotecas de mídia, como ShutterStock.
- A Meta disponibilizou o MusicGen para experimentação no Github.
O MusicGen funciona a partir de comandos simples de texto:
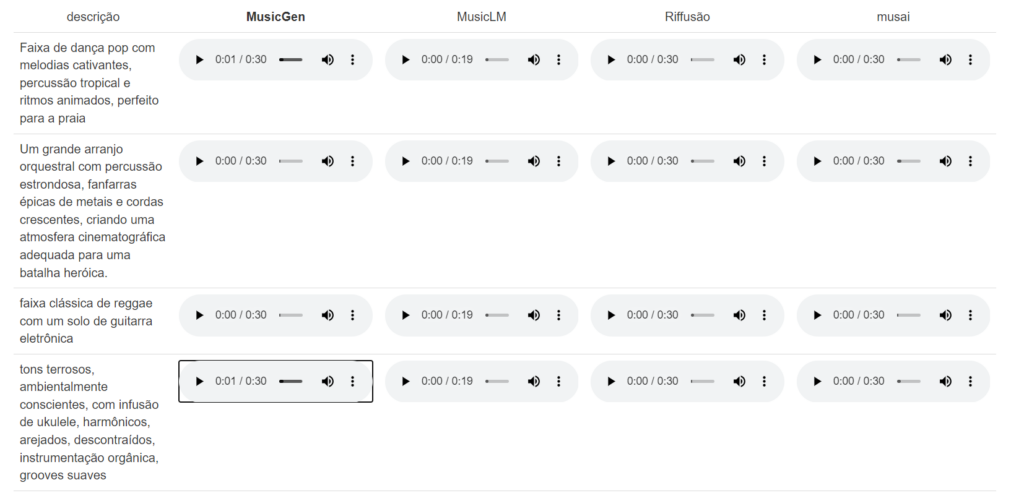
No exemplo exibido, a seguinte descrição foi dada:
“Uma mistura dinâmica de hip-hop e elementos orquestrais, com cordas e metais arrebatadores, evocando a energia vibrante da cidade.”
O resultado foi esse:
- Os pesquisadores da Meta publicaram um artigo descrevendo o treinamento do MusicGen e os desafios éticos que os modelos generativos em larga escala apresentam.
- Os envolvidos reconhecem que os modelos generativos podem representar uma competição desleal para os artistas, mas acredita que, através do desenvolvimento de controles mais avançados, esses modelos podem ser úteis tanto para amadores quanto para profissionais da música.
- Mais detalhes sobre a interface da plataforma e layout ainda não foram divulgados.
Veja também:




