O Google DeepMind acaba de lançar o FACTS Grounding, um novo benchmark projetado para avaliar a capacidade dos LLMs de gerar respostas factuais e abrangentes com base em documentos fornecidos, evitando alucinações.
PUBLICIDADE
Detalhes do lançamento
- O FACTS usa 1.719 exemplos, cada um com um documento, uma instrução do sistema e uma solicitação do usuário, para testar a capacidade de produzir respostas longas e fundamentadas.
- Três modelos de IA (Gemini 1.5 Pro, GPT-4o e Claude 3.5 Sonnet) servem como juízes, avaliando as respostas quanto à precisão e ao atendimento às solicitações do usuário.
- As pontuações são agregadas em todos os juízes e exemplos, com os resultados publicados em um leaderboard público do Kaggle, que será atualizado à medida que novos modelos surgirem.
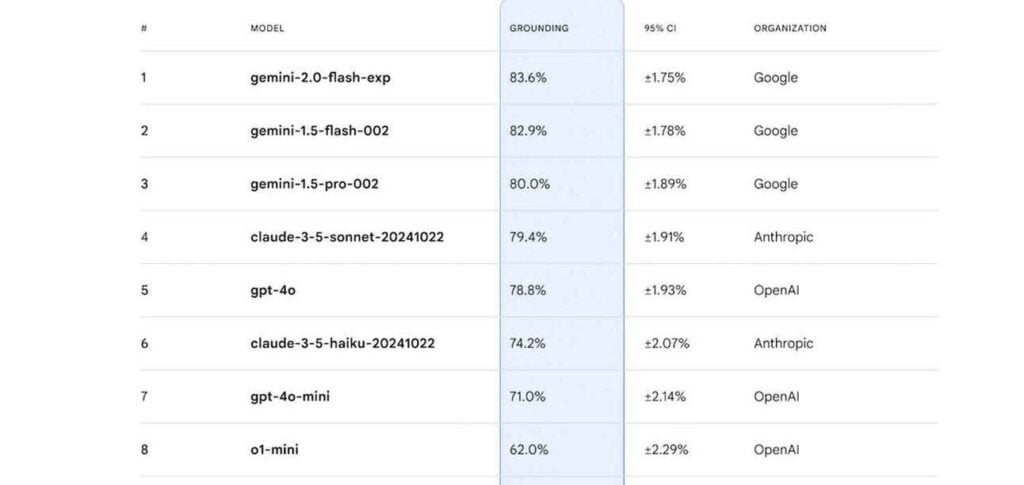
- Os modelos Gemini do Google atualmente lideram o ranking, com o Gemini 2.0 Flash Experimental alcançando a pontuação mais alta, 83,6%, em fundamentação factual.
Por que isso importa
As alucinações continuam a afligir até mesmo os LLMs mais avançados, limitando a confiabilidade e os casos de uso do mundo real. O FACTS Grounding fornece uma maneira mais sofisticada de medir o progresso em uma área de desenvolvimento extremamente importante para a inteligência artificial (IA), concentrando-se em respostas fundamentadas e usando uma abordagem de julgamento multi-LLM.
Leia também:



