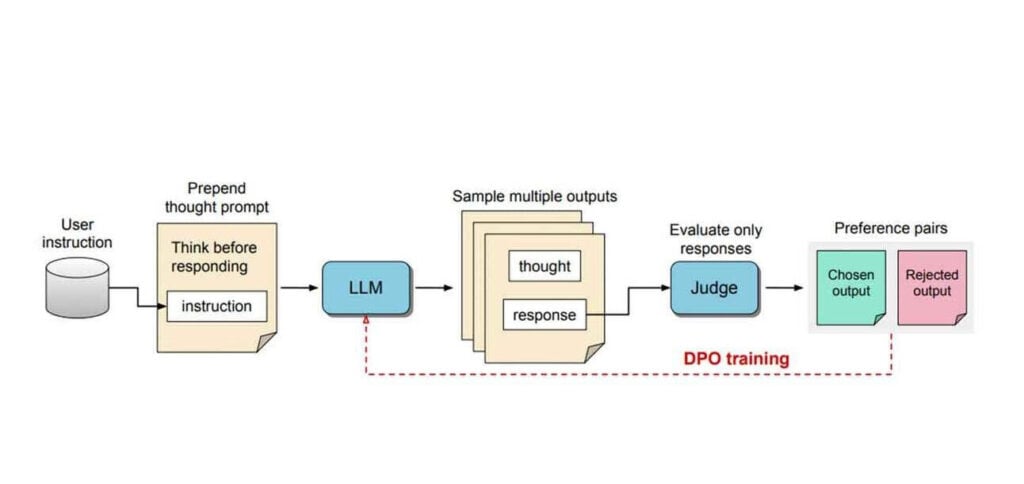
Pesquisadores da Meta apresentaram recentemente um novo método chamado Otimização de Preferência de Pensamento (TPO) para treinar grandes modelos de linguagem a “pensar” antes de responder a instruções gerais – não apenas tarefas de raciocínio.
PUBLICIDADE
Os detalhes
- O TPO solicita que os modelos gerem pensamentos internos antes de responder às instruções do usuário, semelhante a como os humanos pensam antes de falar.
- Os pensamentos da IA são mantidos privados, com apenas a resposta final mostrada aos usuários – com a inteligência artificial (IA) usando tentativa e erro sem supervisão direta para otimizar as saídas.
- O TPO supera os modelos padrão em benchmarks-chave para tarefas não relacionadas a raciocínio, como marketing e redação criativa, mas declina em tarefas relacionadas a matemática.
- A abordagem se baseia na recente pesquisa “Strawberry” da OpenAI e no lançamento do modelo o1, que leva tempo para raciocinar.
Por que isso importa
Yann LeCun, da própria Meta, pode zombar da noção, mas esse método mostra o potencial da IA de “pensar” para tarefas mais amplas do que apenas matemática e raciocínio. Ao permitir que os modelos aprendam processos de pensamento úteis de forma independente, o TPO também pode habilitar assistentes de IA mais capazes e flexíveis em uma ampla gama de domínios.
Leia também:



