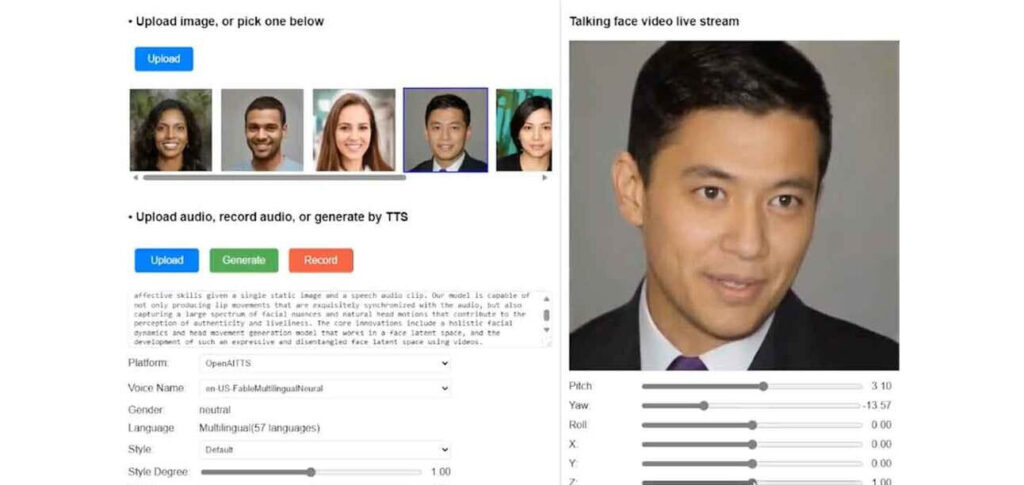
A Microsoft acaba de revelar a VASA-1, um novo modelo de inteligência artificial (IA) capaz de gerar vídeos incrivelmente realistas de pessoas falando a partir de uma única imagem estática e um clipe de áudio.
PUBLICIDADE
🇬🇧 Subscribe to the best newsletter about AI (in English 🇬🇧) 🇧🇷 Assine a melhor newsletter sobre IA (em português 🇧🇷)
Como funciona
- A VASA-1 precisa apenas de uma foto e um arquivo de áudio com a fala para criar um vídeo realista da pessoa falando, com sincronização labial e animações expressivas.
- O modelo pode gerar expressões faciais complexas, movimentos naturais da cabeça e até performances de canto realistas, indo além da simples sincronização labial.
- Os usuários podem controlar aspectos do vídeo gerado por meio de barras deslizantes, como a direção do olhar, a distância da cabeça e o tom emocional.
Por que isso é importante
- A VASA-1 representa um grande salto tecnológico, com potenciais aplicações em áreas como avatares virtuais, jogos e animação por computador.
- No entanto, apesar de ser apenas uma demonstração de pesquisa, a capacidade de gerar deepfakes incrivelmente realistas já está aqui – o que tem implicações significativas para as próximas eleições e para o mau uso por pessoas mal-intencionadas.
Leia também: