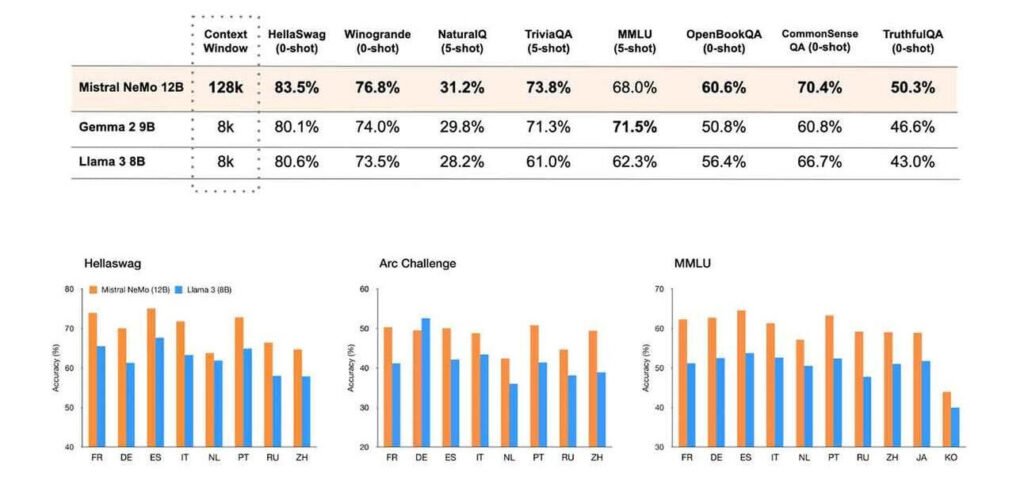
A Mistral AI e a Nvidia acabaram de apresentar o Mistral NeMo, um novo modelo de linguagem pequeno de código aberto com 12 bilhões de parâmetros que supera concorrentes como Gemma 2 9B e Llama 3 8B em benchmarks-chave, além de um aumento massivo da janela de contexto.
PUBLICIDADE
Os detalhes
O NeMo possui uma janela de contexto de 128k tokens e oferece desempenho de ponta em raciocínio, conhecimento de mundo e precisão de codificação para sua categoria de tamanho. O modelo também se destaca em conversas de múltiplas turnos, matemática e raciocínio de senso comum, tornando-o versátil para diversas aplicações empresariais. A Mistral também introduziu o ‘Tekken’, um tokenizador que representa texto de forma mais eficiente em mais de 100 idiomas, permitindo 30% mais conteúdo dentro da janela de contexto. O NeMo foi projetado para rodar em uma única GPU NVIDIA L40S, GeForce RTX 4090 ou RTX 4500, trazendo poderosas capacidades de IA para hardware empresarial padrão.
Por que isso importa
Modelos de linguagem pequenos estão tendo seu momento – e estamos rapidamente entrando em uma nova era de lançamentos de IA que não sacrificam poder por tamanho e velocidade. A Mistral também continua sua impressionante semana de lançamentos, mostrando sua força no código aberto e competindo com os gigantes da indústria.
Leia também:



