A Nvidia acaba de lançar o Nemotron-4 340B, uma família de modelos de linguagem open-source projetados para gerar dados sintéticos de treinamento de alta qualidade e construir aplicações de inteligência artificial (IA) poderosas em diversos setores.
PUBLICIDADE
Como funciona
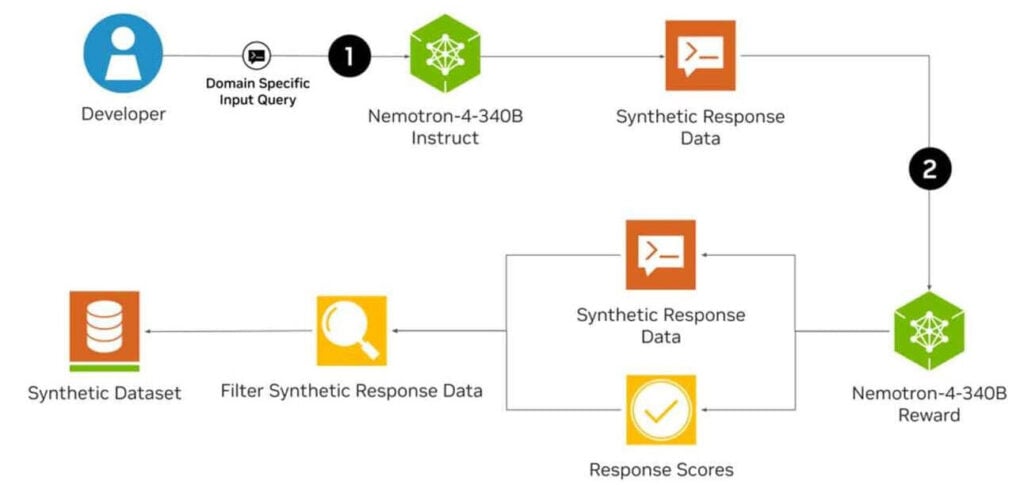
Os três modelos (Base, Instruct e Reward) formam um “pipeline” para criar dados sintéticos para treinar novos e poderosos LLMs (Modelos de Linguagem Grande, na sigla em inglês).
- O Instruct cria dados sintéticos de treinamento de alta qualidade (e foi treinado em 98% de dados sintéticos),
- enquanto o Reward filtra os dados para encontrar os exemplos de melhor qualidade.
Os modelos Nemotron-4 igualam ou superam concorrentes open-source como Llama-3, Mixtral e Qwen-2 em uma variedade de benchmarks.
Além disso, a Nvidia também lançou o Mamba-2 Hybrid, um modelo seletivo de espaço de estado (SSM) que superou em precisão LLMs baseados em transformadores similares.
PUBLICIDADE
Porque isso é importante
A Nvidia acaba de disponibilizar gratuitamente uma família de modelos open-source que não apenas corresponde aos recursos de alguns dos principais concorrentes da área, mas também se destaca na criação de dados sintéticos necessários para continuar aprimorando novos LLMs. A gigante fabricante de chips é uma potência de IA com muitos talentos.
Leia também: