A OpenAI e os autores do SWE-bench colaboraram para redesenhar o popular benchmark de engenharia de software e lançar o ‘SWE-bench Verified’, um subconjunto validado por humanos do benchmark original.
PUBLICIDADE
Os detalhes
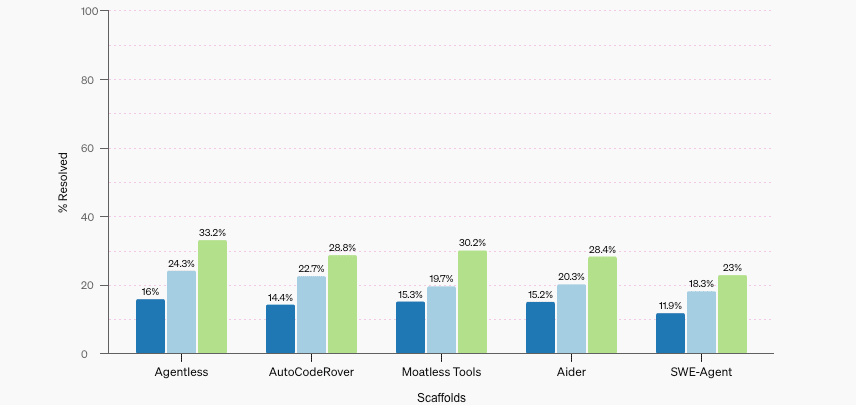
O SWE-bench Verified aborda problemas do benchmark original, como testes unitários excessivamente específicos e ambientes de desenvolvimento não confiáveis que levam a avaliações incorretas do desempenho da IA. O novo subconjunto inclui 500 amostras verificadas por desenvolvedores de software profissionais humanos para tornar a avaliação de modelos no SWE-bench mais fácil e confiável. No SWE-bench Verified, o GPT-4o resolve 33,2% das amostras, e o melhor scaffold de código aberto, Agentless, dobra sua pontuação anterior para 16%. A tabela de classificação para o SWE-bench Verified não inclui o Genie da Cosine, sobre o qual escrevemos ontem, que quebrou a pontuação mais alta no antigo benchmark em mais de 10%.
Por que isso importa
a avaliação precisa da IA em tarefas de nível humano, como codificação, é crucial para a transparência e a avaliação do risco da IA. No entanto, a colaboração da OpenAI com o SWE-bench é uma faca de dois gumes – embora melhore o benchmark, também levanta questões sobre potenciais conflitos de interesse, especialmente com os rumores do ‘Projeto Strawberry’ esquentando.
Leia também: