Com o Stable Audio, os usuários podem inserir prompts de texto para gerar faixas de áudio com o comprimento desejado. Por exemplo, um usuário pode inserir “Pós-Rock, Guitarras, Kit de Bateria, Baixo, Cordas, Sentimental, 125 BPM” para gerar uma faixa de 95 segundos de música pós-rock com um clima eufórico.
PUBLICIDADE
Veja um exemplo de áudio criado com a ferramenta:
De acordo com o comunicado oficial de lançamento, o modelo fundamental do Stable Audio foi treinado usando músicas e metadados da AudioSparx, uma biblioteca de músicas. A empresa alega que o modelo é capaz de renderizar 95 segundos de áudio estéreo a uma taxa de amostragem de 44,1 kHz em menos de um segundo em uma GPU NVIDIA A100.
O Stable Audio é baseado em uma arquitetura de difusão latente que compreende vários componentes, incluindo um codificador automático variacional (VAE), um codificador de texto e um modelo de difusão condicionado baseado em U-Net.
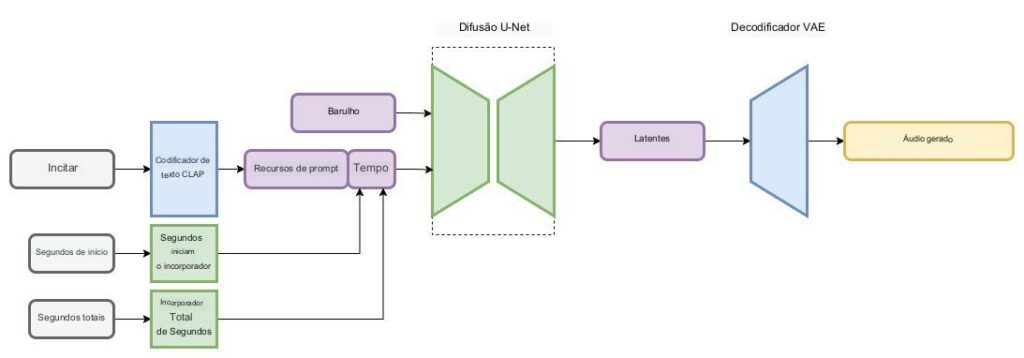
O VAE transforma o áudio estéreo em uma codificação latente compacta, resistente ao ruído e reversível com perda. Essa codificação facilita a geração e o treinamento mais rápidos em comparação com o trabalho direto com amostras de áudio bruto.
PUBLICIDADE
A arquitetura de difusão latente aproveita os dados de áudio, levando em consideração os metadados do texto, a duração do arquivo de áudio e a hora de início. Essa abordagem permite o controle do conteúdo e da duração do áudio gerado.
O Stable Audio está disponível em duas versões: uma versão gratuita com recursos limitados e uma versão Pro com recursos estendidos. A versão Pro oferece faixas estendidas de 90 segundos, adequadas para projetos comerciais.
“Esperamos que o Stable Audio capacite entusiastas da música e profissionais criativos para gerar novo conteúdo com a ajuda da IA”, disse Emad Mostaque, CEO da Stability AI.
Veja também: