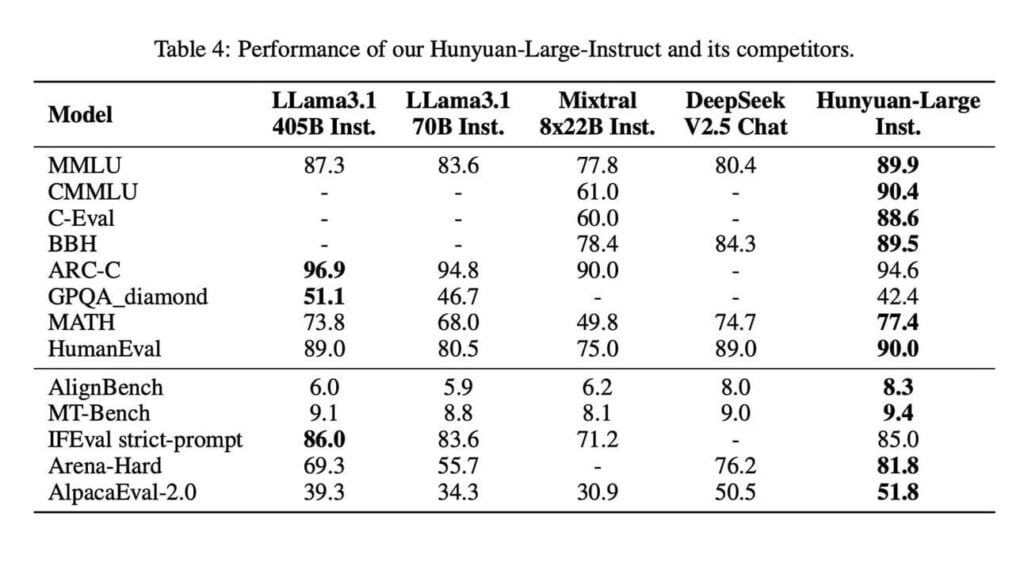
A Tencent acaba de lançar o Hunyuan-Large, um novo modelo de linguagem de código aberto que combina escala com uma arquitetura Mixture-of-Experts (MoE) para alcançar desempenhos comparáveis a rivais como o Llama-405B.
PUBLICIDADE
Os detalhes
O modelo possui 389 bilhões de parâmetros no total, mas ativa apenas 52 bilhões para eficiência, usando estratégias de roteamento inovadoras e técnicas de taxa de aprendizado. O Hunyuan-Large foi treinado em 7 trilhões de tokens (incluindo 1,5 trilhão de dados sintéticos), permitindo desempenho de ponta em tarefas de matemática, codificação e raciocínio.
O modelo da Tencent alcançou 88,4% no benchmark MMLU, superando os 85,2% do LLama3.1-405B, apesar de usar menos parâmetros ativos. Por meio de técnicas especializadas de treinamento de contexto longo, o modelo também suporta comprimentos de contexto de até 256K tokens, o dobro de rivais semelhantes.
Por que isso importa
Modelos de código aberto de grande escala continuam a acelerar. Os resultados impressionantes da Tencent com menos parâmetros ativos podem remodelar como pensamos em escalar sistemas – potencialmente oferecendo um caminho mais eficiente em vez de simplesmente tornar os modelos maiores.
PUBLICIDADE
Leia também:



