Uma pesquisa da Microsoft Research revelou que agentes de inteligência artificial (IA) – mesmo aqueles impulsionados pelos modelos mais avançados disponíveis – ainda lutam com a maioria das tarefas de depuração de software que programadores humanos resolvem rotineiramente.
PUBLICIDADE
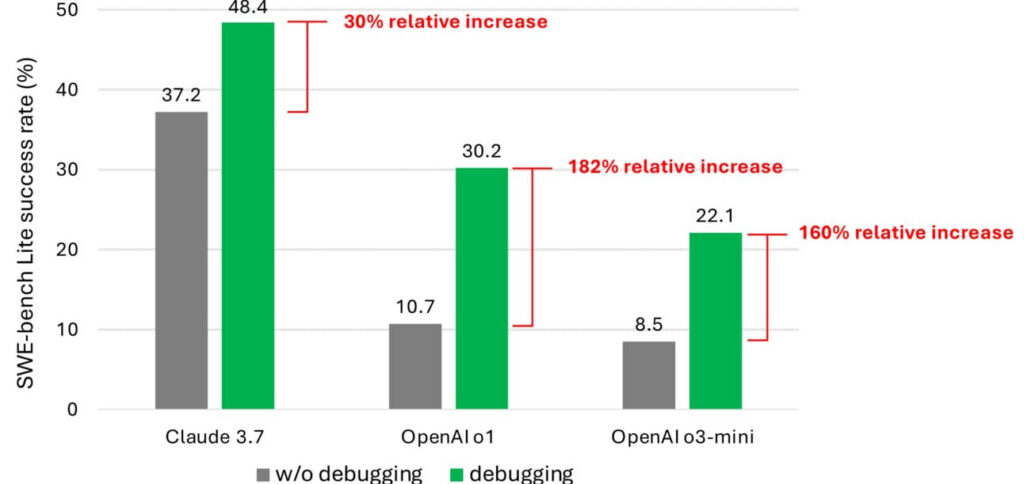
Detalhes do estudo
- A Microsoft utilizou nove LLMs (Large Language Models), incluindo o Claude 3.7 Sonnet, para impulsionar um “agente baseado em um único prompt” encarregado de 300 problemas de depuração do SWE-bench Lite.
- No teste, o agente teve dificuldades para concluir metade das tarefas atribuídas, mesmo utilizando modelos de ponta que se destacam na codificação como base.
- Com ferramentas de depuração, o 3.7 Sonnet teve o melhor desempenho, resolvendo 48,4% dos problemas, seguido pelo o1 e o3-mini da OpenAI, com taxas de sucesso de 30,2% e 22,1%, respectivamente.
- A equipe descobriu que a lacuna de desempenho se deve à falta de dados de tomada de decisão sequencial (rastreamentos de depuração humana) no corpus de treinamento dos LLMs.
Por que isso é importante
Enquanto investidores e executivos de empresas como Google e Meta continuam a investir bilhões em agentes de codificação de IA, este estudo serve como um lembrete da realidade do estado atual. Apesar do progresso impressionante na geração de código, a IA ainda fica significativamente aquém na depuração, uma das habilidades mais cruciais da programação.
Leia também:


