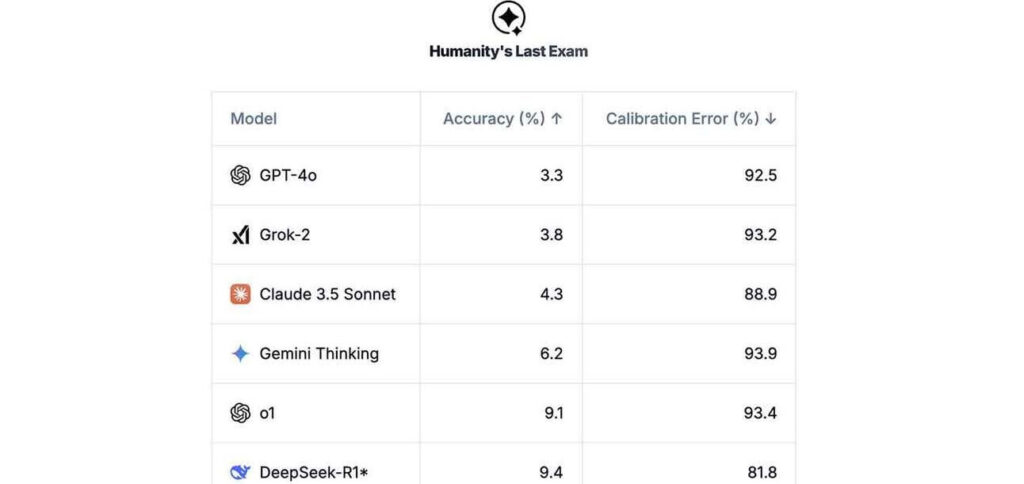
O Center for AI Safety e a Scale AI lançaram o “Humanity’s Last Exam” (O Último Exame da Humanidade), um novo desafio para testar o conhecimento acadêmico de modelos de linguagem de grande porte (LLMs). Esses modelos estão ficando tão avançados que os testes atuais já não são suficientes para avaliá-los adequadamente.
PUBLICIDADE
Detalhes do Humanity’s Last Exam
- O desafio inclui 3.000 perguntas elaboradas por especialistas em mais de 100 áreas do conhecimento, com contribuições de instituições de 50 países.
- Mesmo os melhores modelos de IA existentes tiveram um desempenho surpreendentemente baixo nesse novo teste, com pontuações abaixo de 10% de acerto.
- As perguntas são de múltipla escolha ou exigem respostas exatas, e 10% delas envolvem a análise de texto e imagens.
- Há um prêmio de US$ 500 mil para incentivar a criação de perguntas de alta qualidade. As melhores perguntas serão premiadas com US$ 5.000 e seus autores serão coautores do projeto.
Por que isso importa
Os melhores modelos de inteligência artificial (IA) atuais já conseguem obter notas acima de 90% em muitos dos testes existentes. O “Humanity’s Last Exam” é crucial para criar novos desafios e avaliar o progresso contínuo desses sistemas cada vez mais avançados. No entanto, considerando a rapidez do desenvolvimento da IA, provavelmente não demorará muito para vermos resultados impressionantes nesse novo teste.
Leia também:


